Transcriptomics
10 stages,
40 embryos,
~120000 cells,
more to come...
Single-embryo Single-cell RNA sequencing Atlas
of zebrafish development
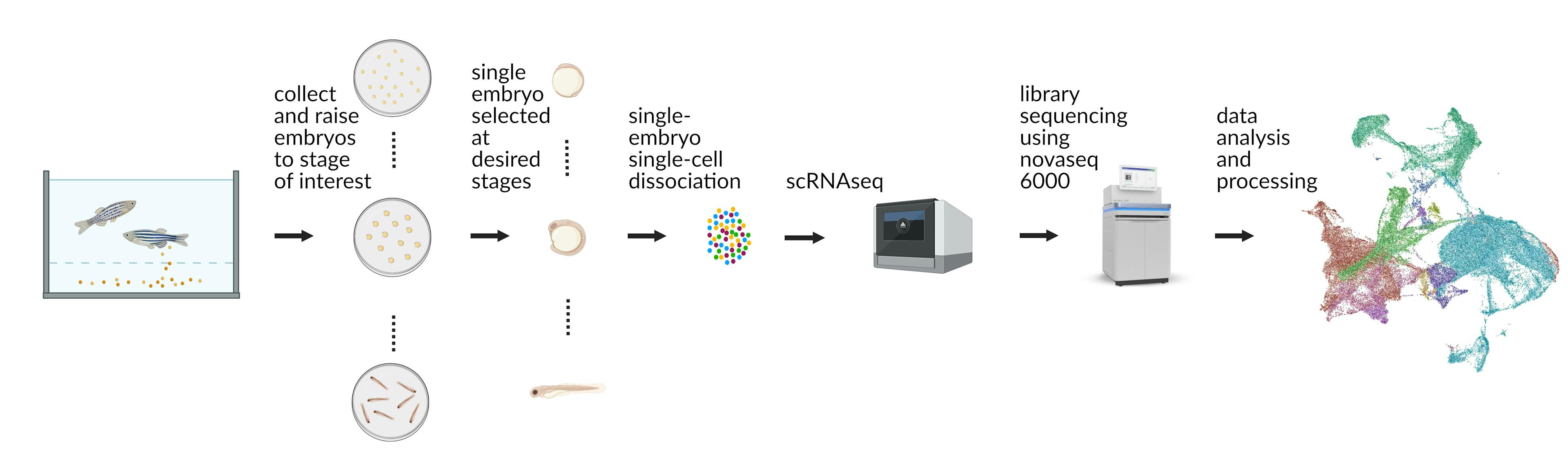
Zebrahub's inaugural release of a single-cell RNA sequencing timecourse dataset, which offers a detailed account of zebrafish development at the resolution of individual embryos. This comprehensive dataset encompasses 10 developmental stages, ranging from end-of-gastrulation embryos to 10-day-old larvae (including bud-stage, 5-, 10-, 15-, 20-, 30-somite stages, as well as 2-, 3-, 5-, and 10-days post-fertilization), with four embryos sequenced per time point and a total of around 120,000 cells analyzed. Our goal is to provide a user-friendly and high-quality single-embryo resolved timecourse dataset that leverages the latest single-cell technologies, providing a comprehensive view of development.
We are committed to producing the highest possible quality, which is why we used a combination of the 10x Chromium (standard and HT) platform for library preparation and the NovaSeq 6000 for sequencing in this first dataset.
Full Dataset

Timepoints


.png&w=640&q=75)
.png&w=640&q=75)
hpf = hours post fertilization
dpf = days post fertilization
Cluster Annotation
We generated UMAPs for each developmental stage by combining the data of all individually sequenced embryos (four embryo replicates per stage). Per time point, we computed Leiden clusters, which we annotated based on the expression of specific enriched genes followed by a literature search using ZFIN, as well as existing published and annotated scRNAseq data (Farrell et al. 2018; Wagner et al. 2018; Farnsworth et al. 2020; Raj et al. 2020).
For the global UMAP we integrated all the developmental stages together to get a temporally coherent cell-type annotation. Annotations were done using information from previously annotated single UMAPs, cross-validated with a literature search based on enriched genes per cluster groups. We leveraged the Zebrafish Anatomy Ontology (ZFA) to provide the community with cell-type annotations that use the controlled vocabulary provided by the ZFA.
Notes on Annotation
Zebrahub is an ongoing project and we are working on improving the resolution of our annotations over time. We welcome collaboration to improve the quality of the cell-type annotations and/or other metadata variables. Therefore if you detect any ambiguity in the current data objects or want to help us on a specific region or cluster please contact us.